
Lab Leaks, Black Holes, and Eggs: Epistemic Case Study Competition
Share



We are running a competition to find the best workflows and methodologies for using AI to produce reliable, trustworthy knowledge bases, grounded in real-world cases. We’re open-minded on the types of submissions we receive and on how they address the problem. We’ve set aside approximately $200k for prizes. Winning submissions may receive a prize from $5k-$50k and if submissions warrant, multiple $50k prizes are possible. Winners may be offered opportunities for further funded work.
You can express interest right away to receive commentary, information, and updates — whether you’d like to participate or are just interested in the outcomes of the competition.
The heights of human epistemic investigation are impressive and valuable, but rare and difficult to reach — see our abridged collection of strong examples.11 Forecasting the shape and capability of future AI is difficult, but we are excited to imagine a world where epistemic investigations of this (and greater!) quality are commonplace. We’re aiming to catalyse that path through activities like this competition. The limiting factor is rarely exquisite insight (though this helps!), and more often diligence, a curious and open mindset, and the time and effort needed to do the thorough work investigating background on a topic: activities AI is well placed to assist with.
Existing AI-assisted knowledge base work demonstrates real pieces of this — agent memory (e.g., Claude Code’s memory and skills), LLM-curated personal wikis (Karpathy’s perhaps the highest-profile), and deep-research tools. But these mostly produce single-user artifacts tuned to one investigator’s context, not the kind that travel, combine, or survive (especially adversarial) scrutiny.
We’re particularly excited by the compounding potential — if structured analyses22 By structure, we mean capturing the relations between different sources, claims, authors, and so on. Who said what and when? What evidence or reasons support that? What counterarguments exist or reasons for doubt? We give further ideas below. Keeping this structure alive means less loss by compression, and preserving space for nuance — even if we don’t consume it right away.
become reusable, refineable artifacts, every serious investigation enables future work, on the same or related topics, and by the same or different people, to reach further from a more solid epistemic foundation. Who knows, you might even solve debate!
This competition provides three challenging case studies — with deliberately varied challenge profiles — and invites you to produce tooling and techniques to help people navigate them. First, the debated and impactful question of COVID-19 origins. Second, the risk that the Large Hadron Collider (LHC) creates synthetic black holes (perhaps destroying the Earth). Third, the health impact of eggs (as a human food source). The tooling should be general: we’ll judge against these and also other difficult case studies.
What we’re looking for
We want to see workflows and methodologies using AI that advance the state of the art in carrying out epistemic investigations and producing compounding knowledge bases. We aren’t asking you to build an entire, robust, fully-featured system. Instead, we’re excited by any submission that advances the state-of-the-art on a component.33 The human urge to apply technology to knowledge-provision isn’t new: consider libraries, citations, indexes, encyclopedias (including Wikipedia), databases, web search — all of which push the frontier in this space.
We’ve found it useful to think of these investigations as being split into several different layers: ingestion, structure, and assessment (more here). When stacked together and operating in concert, they’d create useful trusted artifacts. Something like a superior deep research, generating and interacting with a structured knowledge base, aimed at the truly epistemically discerning consumer.
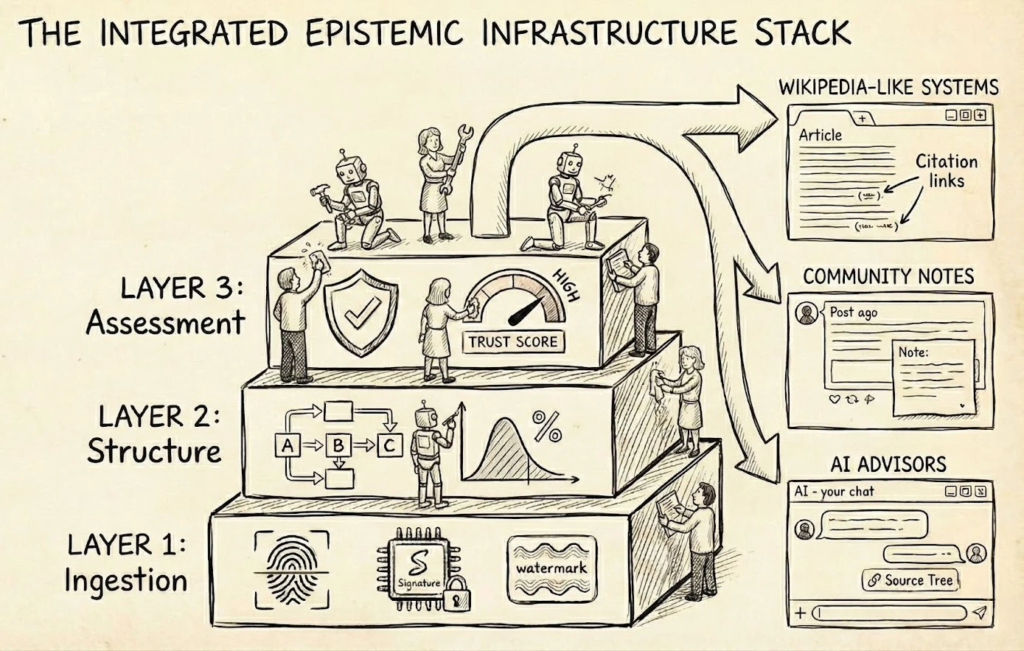
Below are a set of ideas for potential desiderata for a workflow. We’d expect most submissions to not be solely focused on a single layer, as we’re guessing for something to be useful it needs to work across the layers — but some discipline in separating these responsibilities may be useful for producing interoperable, shareable, compounding benefits.
Ingestion
How do you take a messy, multi-source evidence base and turn it into something structured enough to reason over?
- Extract and attribute claims to specific sources, with provenance metadata (who said what, when, in what context).
- Identify when the same claim appears across multiple sources in different forms.
- Search for resources with bearing on topics and subtopics at hand.
- Capture useful metadata tags. For example relating sources and claims to topics and other sources (toward structure) or about methodologies, deference, and assumptions (toward assessment).
Structure
How do you document the relationships between claims so that the full shape of the argument becomes navigable?
- Resolve the inference structure: which claims and evidence are offered as support for which other claims.
- Represent the discourse structure: where people are addressing different sub-questions and perhaps how they are tracking those relating to an overall inquiry — there may be explicit, and sometimes implicit, differences of emphasis.
- Capture relationships regarding “similar but not identical” claims. These could be different ways of framing conditions or caveats to statements, or different estimates of uncertainty for quantities or propositions.
- Track how the structure evolves over time.
Assessment
How do you evaluate what to actually believe, or what to look at next, given everything above?
- Identify rhetorical moves that carry more persuasive weight than evidential weight.
- Flag correlated evidence being treated as independent.
- Identify cruxes, i.e. the specific factual or inferential disagreements that, if resolved, would most change the overall picture (perhaps drawing on debate structure).
- Surface what’s missing — important sources or perspectives that aren’t represented in the working knowledge base, toward further data collection (or hinting at additional primary information collection and reasoning).
- Provide frameworks for calibrating confidence that account for out-of-model error, adversarial information environments, and the limits of any single analyst’s expertise.
- Distinguish what the debate settled from what it merely performed settling.
What a good entry looks like
We’ll offer a minimum of $5k to entries which we judge to meaningfully improve on the state of the art in faithful, scalable AI-assisted investigations, and up to $50k for entries which are truly inspiring to us. This might be by (for example) reliably producing accessible, thorough, highly-interoperable knowledge-enabling content across diverse domains which is readily shared and expanded on by others.
We aren’t prescribing a single, specific type of submission.44 Written discussions should aim to not exceed 10 pages, not including appendix-like material and worked examples. Worked examples and fully-fledged example knowledge bases can be arbitrarily sized (within reason) but should be navigable. Consider including curated pointers to particularly effective regions of worked examples. Code should either be brief, legible (pseudo)code or well-documented and ready to install and run with close to a single click. See here for more detail. A couple shapes we’d be excited to see:
- A spec describing a step-by-step process of a human-AI workflow for producing a structured epistemic analysis of a complex dispute. Demonstrate it on multiple part(s) of at least two cases. The workflow can incorporate human steering and be subjective in places, but should let others (even with differing beliefs and preferences) usefully pick up where another left off, and it should gracefully scale to mostly-or-entirely ‘hands free’. Make clear where your design choices are uncertain, and be transparent about where you’re making tradeoffs, and why.
- A prototype tool (most likely a pipeline involving LLMs) that implements one or multiple layers of the stack, demonstrated in a repeatable way on each of the case studies. Minimally, it should substantially accelerate users’ investigation of a topic, and ideally it should produce reusable, shareable knowledge artefacts which stand up to adversarial pressure.
- A protocol enabling interoperability and compounding without flattening the underlying material, demonstrated with reference to our cases. How can we navigate the tension between interoperability and nuance? What does a format look like that’s flexible and general enough to link diverse subtopics and complex, multi-perspective investigations while preserving important detail? How can it be maintained over time in a way that plays well with newly-emerging sources, a diverse and changing user base, and an expanding frontier of AI capability for tooling?
A submission might be of a different shape, look like one of these, or may combine these (for example a spec including protocol discussion and a reference prototype). Some stepping-stone alternatives which could contribute to putting a team in a great position to achieve the biggest wins (but which we expect are unlikely to win the biggest prizes without follow-up work):
- A comparative analysis repeatably55 Ideally such that judges can easily reimplement on a new case. applying two or more different AI assessment methodologies to the same (sub-)questions from the topic, with explicit discussion of where they agree and diverge. What downstream considerations do they best enable? What are their strengths and shortcomings? What kinds of supporting epistemic metadata would help them to work better?
- A critique with counterexamples of an otherwise promising approach, demonstrating the importance of further work or indicating less tractability than we might have thought.
Optionally, submit a description of your plan or a briefer, less complete implementation of it by Jun 21, 2026, and we will weigh in on whether the work seems on track for a prize (and potentially provide feedback). Use the main submission form and check the early feedback box.
What we care about most: Would this actually help someone reason better about this case? Does it generalize? Does it scale with improvements to AI or more compute? Does it compound, with multiple people or teams building on each others’ work?
We’ll ask judges to use the following criteria when assessing submissions: Epistemic Case Study Competition – Judging Criteria.
In addition to the potential prizes, strong entries that demonstrate real promise may also lead to an offer for further funded work with us (we estimate an 75% chance that a $50k-winning entry receives an offer like this).66 One type of further work might be incorporating workflows into forecasting and prediction — perhaps grounded in forecasting bot competitions.
Please use this linked form to submit your entry; entries are due by Jul 19, 2026.
FLF’s general contest rules apply.
Prize structure
We’ve allocated roughly $200k for this competition with the size of any individual award reflecting how much an entry moves us. We’d rather award fewer, larger prizes for entries that genuinely impress us than spread the pool out. If a wave of strong work arrives, we’ll happily expand the total prize pool.
Concretely, we expect to award up to:
- $50k → for an entry or entries we find truly inspiring. The kind of submission that changes how we think about the problem or that we’d want to point to as a new reference point for AI-assisted epistemic work. We may not award it at all – or – we may also award it more than once if multiple entries clear that bar.
- $5k to $50k → for entries that meaningfully advance the state of the art, whether across the full stack or on a well-defined piece of it (ingestion, structure, or assessment). The size of each award reflects how far the work pushes the field and we expect several entries to land somewhere in this range.
- Continuation funding → beyond prize money, we expect to fund individuals or teams to keep building, on terms agreed case by case. For the strongest entries this may be the real prize: an ongoing relationship with FLF and a path to sustained work on the stack. We’ll raise this with finalists after judging.
Interested in participating or following along?
Want to compete, follow along, or join the conversation? Express interest to receive updates, commentary, and see how you can participate as the competition unfolds.
Why we’re doing this
We’re building toward what we call a full epistemic stack, layered infrastructure for making the provenance, structure, and assessment of knowledge transparent and traversable at scale. We think recent AI advances make this newly tractable, but the hard problems are in methodology and workflow design, as well as usability, not just capability.
Not only do we expect these tools to be of widespread benefit, but we expect some organizations like ours to be eager early adopters. FLF hopes to meaningfully inform its strategy and prioritisation based on insights from these tools, meaning that great work here could move millions of dollars per year and help us (and others) be more effective.
We’re excited to see what you build.
The case studies
COVID
In early 2024, a $100,000 judged debate took place between Saar Wilf (founder of Rootclaim) and Peter Miller on the origins of COVID-19. Over 15 hours of structured argument, two smart people marshalled epidemiological data, viral genetics, Bayesian inference, and institutional analysis to reach opposite conclusions. Two expert judges ruled decisively for zoonosis. Six independent Bayesian analyses of the same evidence spanned 23 orders of magnitude.
For more read Scott Alexander’s detailed writeup. We feel that the debate videos, judge decisions, and comment threads it links to form one of the richest publicly available records of a complex real-world epistemic dispute on an important issue.
And yet all this information is still incredibly difficult to navigate, interrogate, and use to inform one’s beliefs.
- It requires significant background expertise to understand the state of play of the debate and make a considered judgement. The debate was overseen by two judges with PhDs who work as a professional microbiologist and applied mathematician, respectively.
- The format, a live video debate, may not be the optimal way for a judge to interact with the material.77 Rootclaim thinks that one reason they lost the debate was that the “structure provided a major advantage to the debater with more memorized knowledge of the issue”.
Further, this intense epistemic effort represents a point in time in a conversation which continues to evolve.
We feel this makes it a strong stress test for tools and methods that aim to make reasoning more transparent, traversable, updateable, and trustworthy.
Your job: craft the AI-assisted methodologies that build a structure to help people navigate this topic successfully.88 We envision these as acting as eventually becoming living knowledge bases, not merely snapshots in time.
Starting material
- Scott Alexander’s writeup of the COVID origins debate (the core case material)
- Judge Will’s decision | Judge Eric’s decision
- Michael Weissman’s Bayesian analysis (an example of a more rigorous independent analysis)
- Rootclaim’s response
- The debate videos: Session 1 | Session 2 | Session 3
Black holes
CERN, home of the world’s largest particle accelerator, the Large Hadron Collider (LHC), has a frequently asked question: Will CERN generate a black hole?
What??
As in some previous science experiments, noting that novel circumstances might produce unprecedented outcomes, some participants had apocalyptic concerns. How were these put to rest? (Were they truly? What does that hinge on?)
Unlike COVID, this is (we hope!) essentially a closed case, and uncontested. It nevertheless rests on a huge body of accumulated and interacting knowledge which enabled scientists (and the officials and public supporting them) to move forward with confidence.
The key challenge here may be in probing this argument for its dependencies and key considerations, and perhaps noting the weakest or most speculative points — all in an accessible way.
Eggs
Are eggs good to eat? Bad to eat? Great in moderation? How can we tell? Does it vary across people, and what predicts this? What else should we be paying attention to here?
This vague and open-ended topic, though mundane, is representative of a huge number of everyday questions — and hopefully also a microcosm of many more impactful debates. Sometimes getting resolution on what are the important things to answer and what are the appropriate ways of knowing is (more than) half of the challenge.